Projects, more markdown, creating data, more functions and a ggplot2 graph
1. Projects
…one small step for a programmer, one giant leap for reproducibility
Create an R Project:
In R, Session > New Session (make this a frequent habit)
File > New Project…
For now, New Directory (but version control coming up soon…) > New Project
Give your project a name (e.g. eds212-day1b)
Click Browse to choose where to put it (this will create a folder on your computer)
Create Project
Discussion - what does this do? Where does it live on your computer? What does it contain?
It helps to stay organized!
Consider how you’ll want to organize all your MEDS projects / code. This is totally up to you, though one suggestion is to create a MEDS/ folder in your computer’s root directory, then a folder for each course (e.g. EDS-212), then add your R Project (e.g. eds212-day1b) inside the appropriate course folder.
Make a new Quarto doc in your project, then follow along (adding notes in the body of your Quarto doc using markdown) with the rest of the session.
There are a couple ways to create a new Quarto doc…
In the top left corner of RStudio, you should see a file with a green “+” icon. Click on that button, then choose Quarto document…. This will open a popup window which will prompt you to provide a title, and optionally, your name as the author. You can also select which output format (HTML, PDF, Word Doc) you’d like to render your Quarto document to (we recommend sticking with HTML). When you click Create, a Quarto doc with a pre-filled YAML header, along with some example text / code (you’ll want to delete this) will be opened for you to edit.
In the Files pane, click on the New Blank File drop down to select Quarto doc…. This will open a completely blank Quarto doc without a YAML header for you to edit. You can create your own YAML by typing a set of gates (---) and adding any desired YAML options between them.
2. Exponents and logs in R
Recall from lecture that logarithms ask a question
\(log_a(b)\) asks, “to what power do I have to raise a to get a value of b?
Some useful “base R” functions:
log() == natural log, aka:
\(ln()\)
\(log_e()\)
log10() == log base 10, aka:
\(log_{10}()\)
exp() == natural exponential, aka:
\(f(x) = exp(x)\)
\(f(x) = e^x\)
What is “base R?”
R is distributed with some helpful base packages, meaning when you install R, a series of packages (containing functions, including those shown above) are also installed. You may hear these referred to as “base R” functions, which makes reference to the fact that they come pre-installed (i.e. you don’t need to install / load additional packages to use them).
Let’s try some! Remember, you’ll need to add a code chunk to write the following code in!
# Euler's number (e) ---exp(1)# all three result in the same value (e^2) ----exp(2)exp(1)^2exp(1)*exp(1)# "to what power do I have to raise `e` to get a value of `e^10.4`?" ---# recall from lecture slide: https://eds-212-essential-math.github.io/course-materials/slides/day1.2-slides.html#/logarithmslog(exp(1)^10.4)# "to what power do I have to raise 10 to get a value of 100?" ----log10(100)# "to what power do I have to raise 2 to get a value of 16?" ----logb(x =16, base =2)
3. Making sequences in R
Sometimes we’ll want to create sequences of values that we can plug into a function to see how an output value changes over a range of inputs.
We can make a sequence of values, stored as a vector in R, using the seq() function. The general structure looks like this:
seq(from = start_value, to = end_value, by = increment)`
For example, to create a sequence from 2 to 18 by increments of 0.3, I would use:
Note that the above sequence ends at 17.9 (the last complete increment). Another option is to specify the length of the output vector instead - like “I want to have 30 values between 2 and 18, evenly spaced.” To do that, use the length = argument within the seq() function.
4. Make the logistic growth function. . . function
Let’s make a function of the logistic growth equation. Recall, the expression for population size at any time t following logistic growth is given by:
\[N_t=\frac{K}{1+[\frac{K-N_0}{N_0}]e^{-rt}}\]
Let’s write it out. When in doubt, parentheses! Keep in mind that you may want to make your argument names something a bit more descriptive. Always ask: What will make future me least likely to mess this up? What would make these function arguments clearest to my collaborators?
Let’s say that for a population of chipmunks in one region, the carrying capacity is 2,580 individuals, the exponential growth rate is 0.32 (yr-1), and time is in years. If the initial population is 230 individuals, what is the estimated population size a time = 2.4 years?
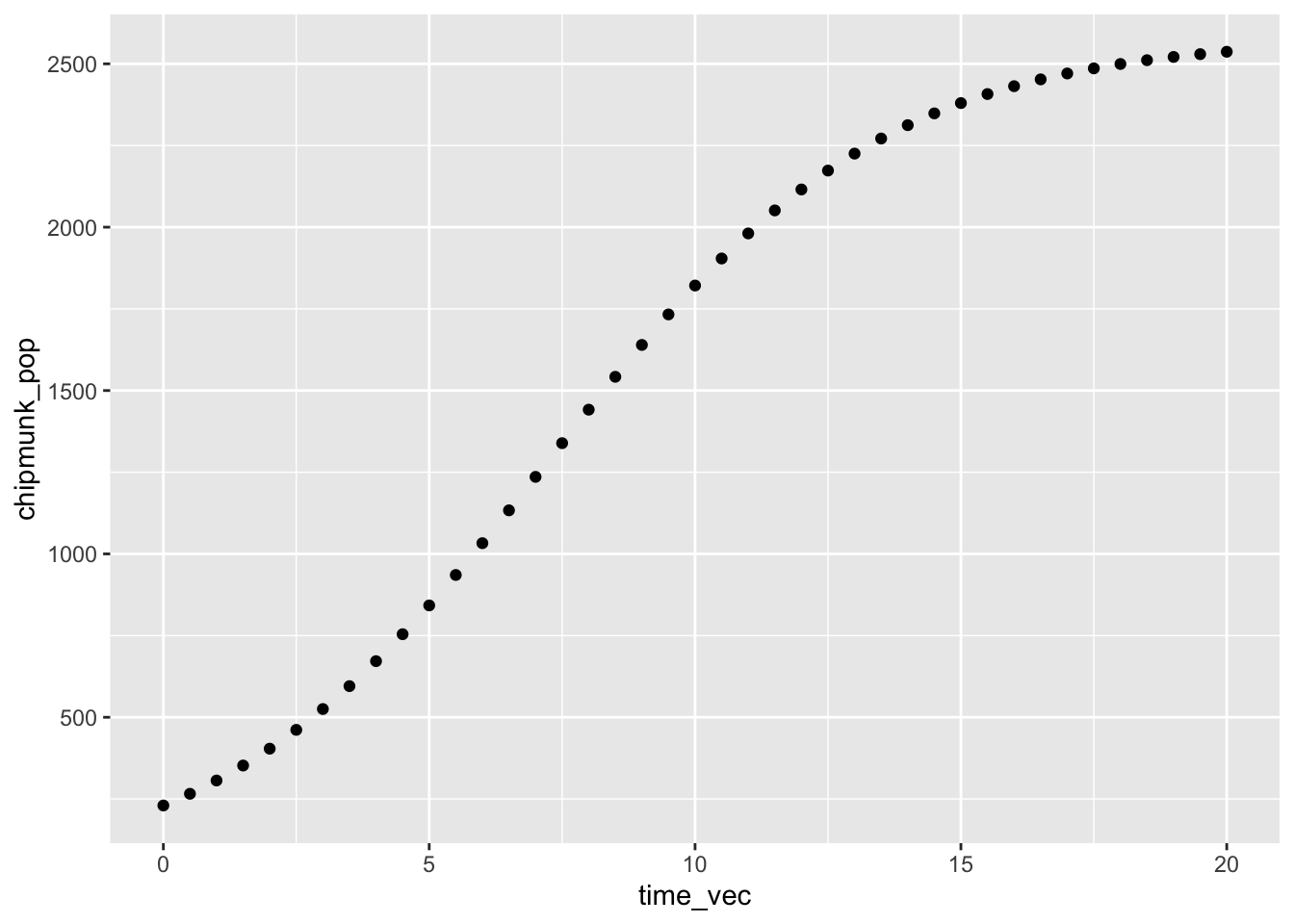
Now let’s say we want to predict (then plot) the estimated population over a bunch of different times. Based on what we’ve learned today, how do you expect we might do that? A sequence of values as the time input!
Let’s make a sequence of times (0 to 20 years, by 1/2 year increments), then use that vector as our time input in the logistic growth model.
# First, create the vector (a sequence of values) ----time_vec <-seq(from =0, to =20, by =0.5)# Then, use that as your time input in the model ----pop_logistic(capacity =2580, init_pop =230, rate =0.32, time_yr = time_vec)
We want to plot those estimated population sizes - but we didn’t store the vector of outputs! Remember - if you want to store an output, using the assignment operator (<-) in R, and check that it exists in your environment.
# assign your model to an object (here, that's called `chipmunk_pop`) ----chipmunk_pop <-pop_logistic(capacity =2580, init_pop =230, rate =0.32, time_yr = time_vec)# Then we can call `chipmunk_pop` ----chipmunk_pop
You will learn a lot more about data visualization throughout MEDS. But let’s make a first rough visualization just for fun using the {ggplot2} package, which is part of the {tidyverse} (more on this in EDS 221).
I really want to know what the {tidyverse} is now though!!
The {tidyverse} is actually a collection of R packages that make doing data science in R (think, data cleaning / wrangling / visualizing) really enjoyable. All of the {tidyverse} packages share a similar design philosophy, grammar, and data structures.
While you can install / import each of the tidyverse component packages separately (e.g. install.packages("ggplot2"), then import using library(ggplot2)), you’ll commonly see folks install the entire{tidyverse} by running:
install.packages("tidyverse")
then load all of the {tidyverse} at the top of a script / Quarto doc:
# load libraries ----library(tidyverse)
We’ll do this together in the next exercise!
Let’s first combine our time sequence (time_vec) and predicted populations (chipmunk_pop) into a single data frame - a table of data where different vectors (we’ll think of these as variables moving forward) are stored in columns.
# combine `time_vec` and `chipmump_pop` into a data frame ----chipmunk_df <-data.frame(time_vec, chipmunk_pop)# ALWAYS look ----head(chipmunk_df)
Load the tidyverse using library(tidyverse), then follow along while we rave about the grammar of graphics to make a basic ggplot graph:
Install the {tidyverse} if you haven’t done so already
Before you’re able to load the {tidyverse} in your Quarto doc, it needs to be installed. If you don’t already done so, you can run install.packages("tidyverse"). in your RStudio Console.