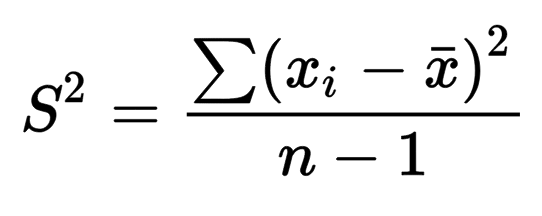Average value of sample observations, calculated by summing all observation values and dividing by the number of observations. E.g. \(mean\;of\;3, 7, 17 = \frac{3+7+17}{3} = 9\)
Pros:
Average value is often useful metric
Commonly reported
Cons:
Susceptible to outliers and skew
Subject to misinterpretation as “most likely value”
Median
Middle value when all observations are arranged in order. If you have an even number of values, the median is calculated as the average of the middle two values. E.g. \(median\;of\;3, 7, 17 = 7\)
Pros:
Less susceptible to skew and outliers
Better as sample size increases
Cons:
Doesn’t take into account the magnitude of all values
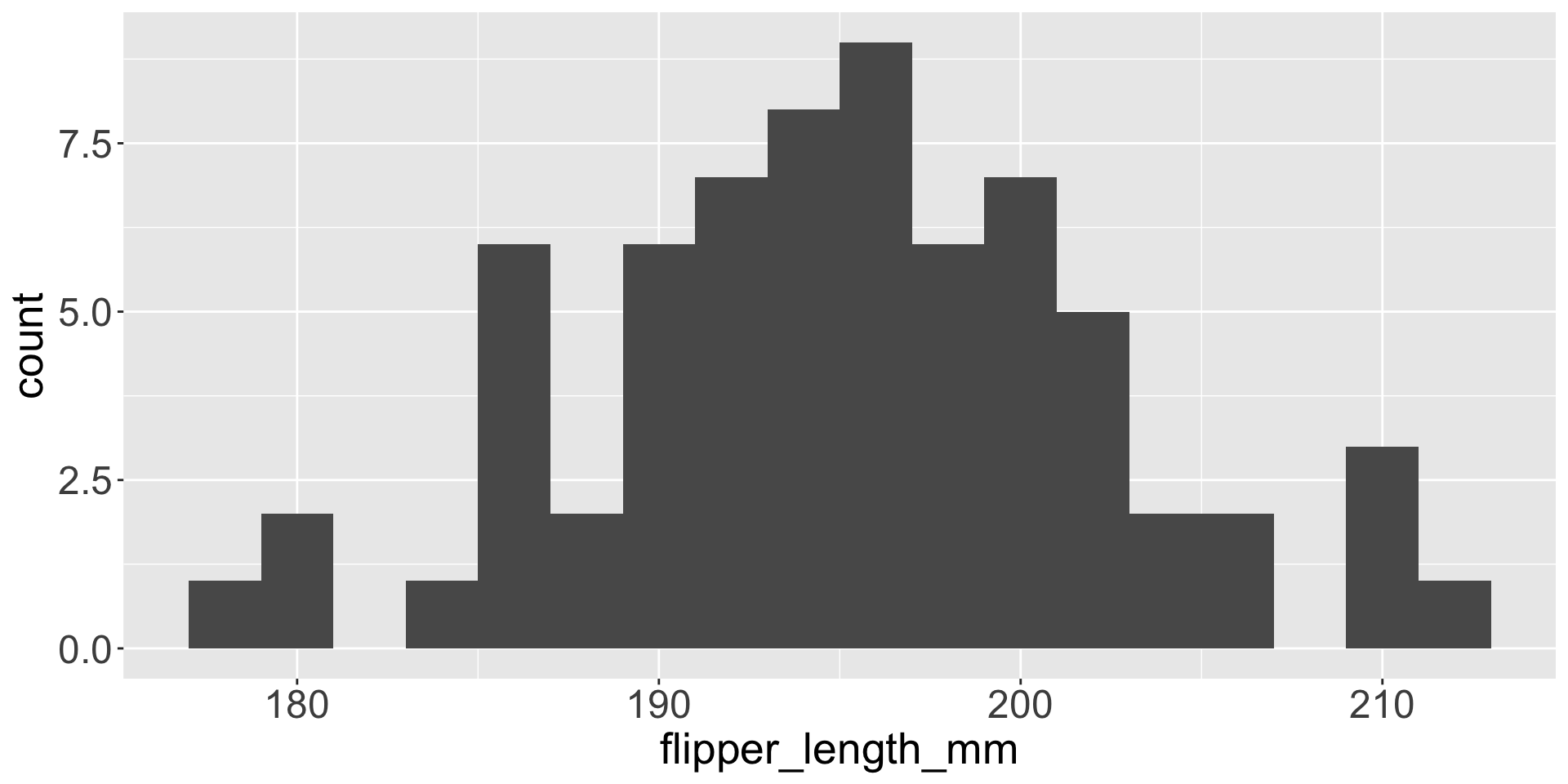
The best way to describe the distribution of the data is to present the data itself.
Variance and standard deviation
Both are measures of data spread.
Variance
Reported in units of measurement squared
Standard deviation
Reported in units of measurement
Variance
Variance: Mean squared distance of observations from the mean
Where \(s^2\) is the sample variance, \(x_i\) is a sample observation value, \(\bar x\) is the sample mean, and \(n\) is the number of observations.
Calculate variance by hand (1/2)
Given these data: \(2, 4, 4, 6, 9\)
Calculate the mean:
\[ mean = \frac{2+4+4+6+9}{5}=\frac{25}{5}=5\] 2. Subtract the mean from each data point and square the result:
Divide by the number of data points minus 1 (\(n\) - 1)
\[Variance = \frac{28}{5-1} = 7\]
Alternatively, in R:
var(c(2, 4, 4, 6, 9))
[1] 7
Standard deviation
Also a measure of data spread, calculated by taking the square root of the variance.
In R:
sqrt(var(c(2, 4, 4, 6, 9)))
[1] 2.645751
# or alternatively, just use sd()sd(c(2, 4, 4, 6, 9))
[1] 2.645751
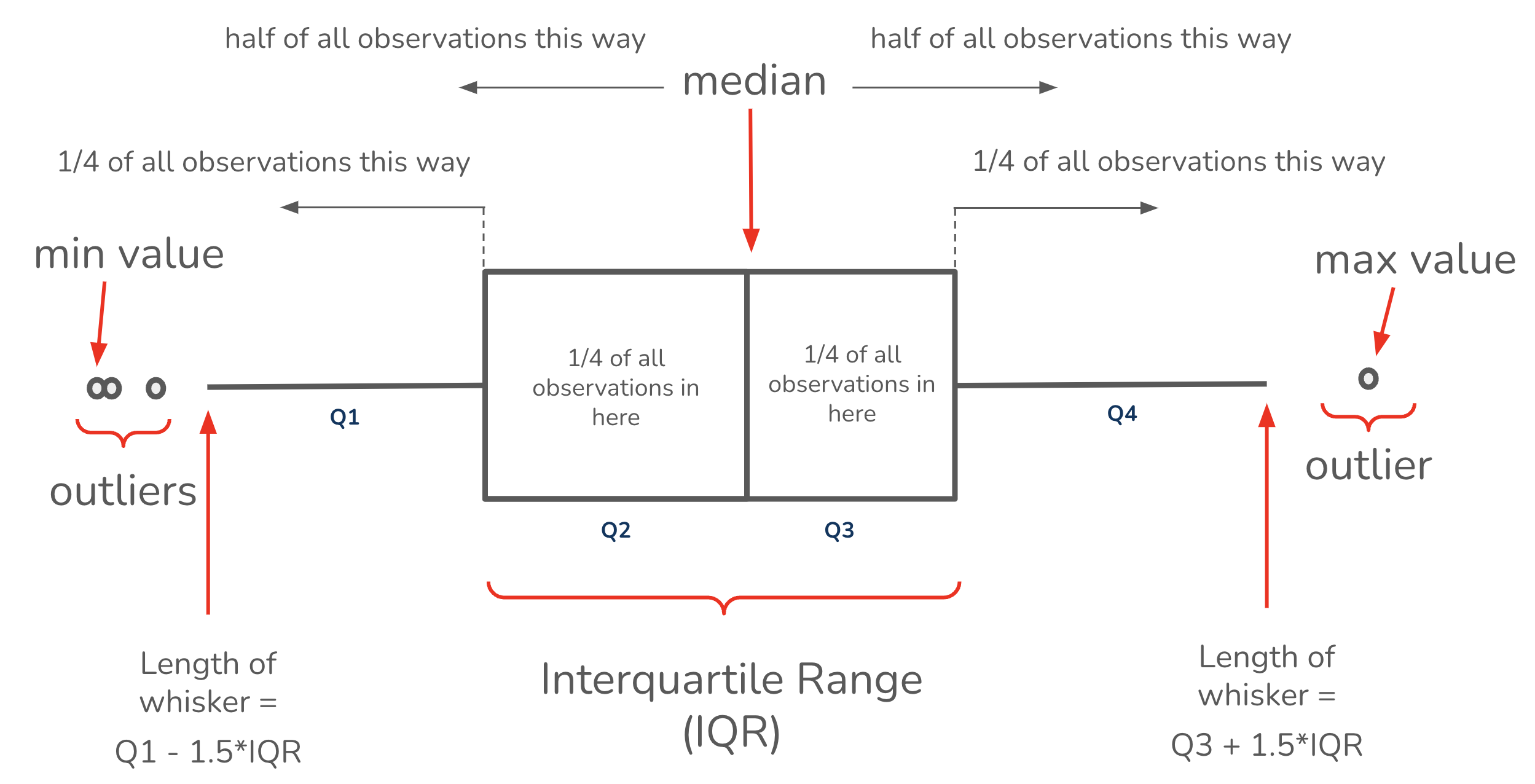
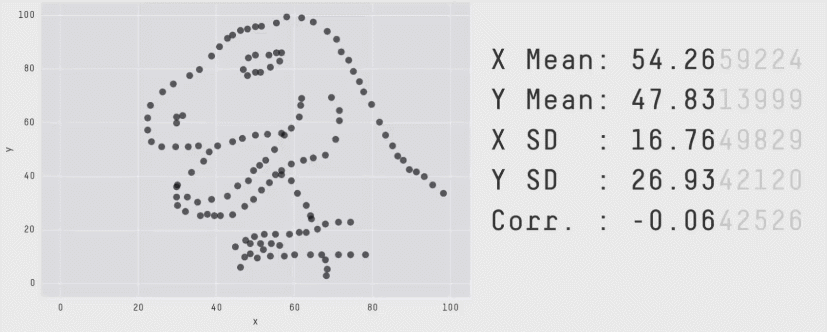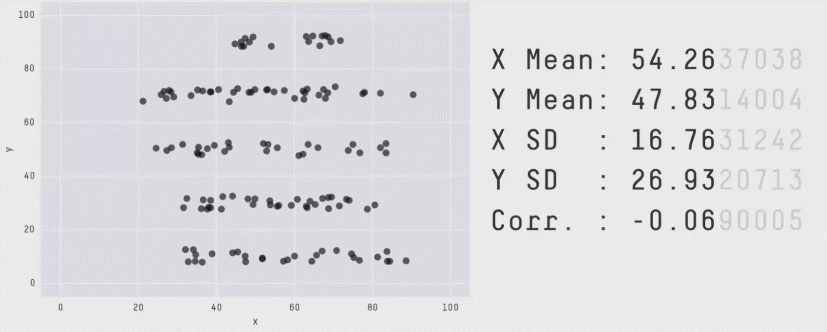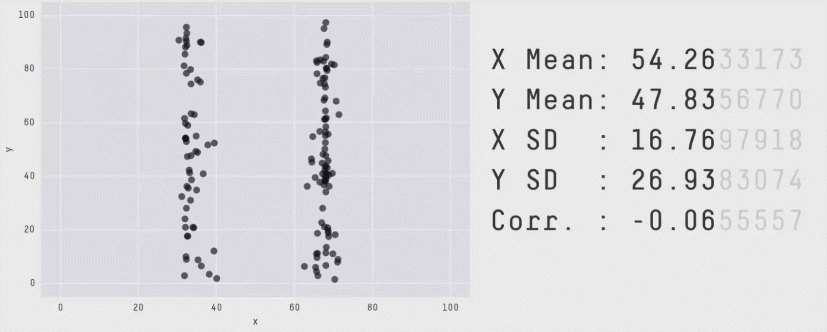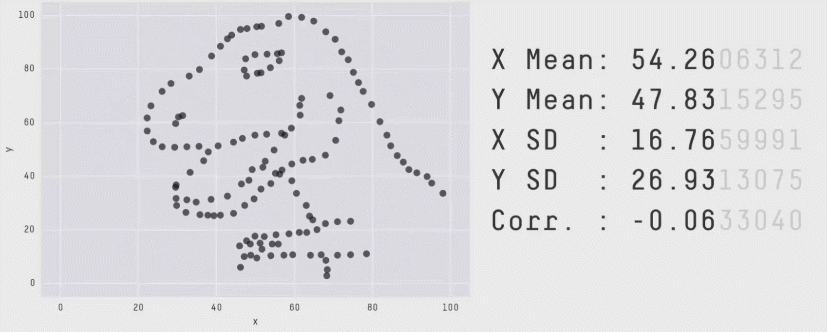
Beware summary statistics alone . . .
Meet the Datasaurus Dozen
Same summary statistics, different distributions
Confidence interval
Confidence interval: a range of values (based on a sample) that, if we were to take multiple samples from the population and calculate the confidence interval from each, would contain the true population parameter X percent of the time.
What it’s NOT:
“There is a 95% chance that the true population parameter is between values X and Y.”
Confidence interval example
Mean shark length is 8.42 \(\pm\) 3.55 ft (mean \(\pm\) standard deviation), with a 95% confidence interval of [6.45, 10.39 ft] (n = 15).
What this DOES NOT mean: There is a 95% chance that the true population mean length is between 6.45 and 10.39 feet.
The true population mean is a fixed value and does not change – the CI either contains this true mean or it does not. There is no probability involved.
What this DOES mean: If we took a bunch of sets of samples from the population (all n = 15), then 95% of the time, the calculated mean would fall within this range.
This statement correctly describes the frequency with which we would expect CIs to capture the mean over many samples.
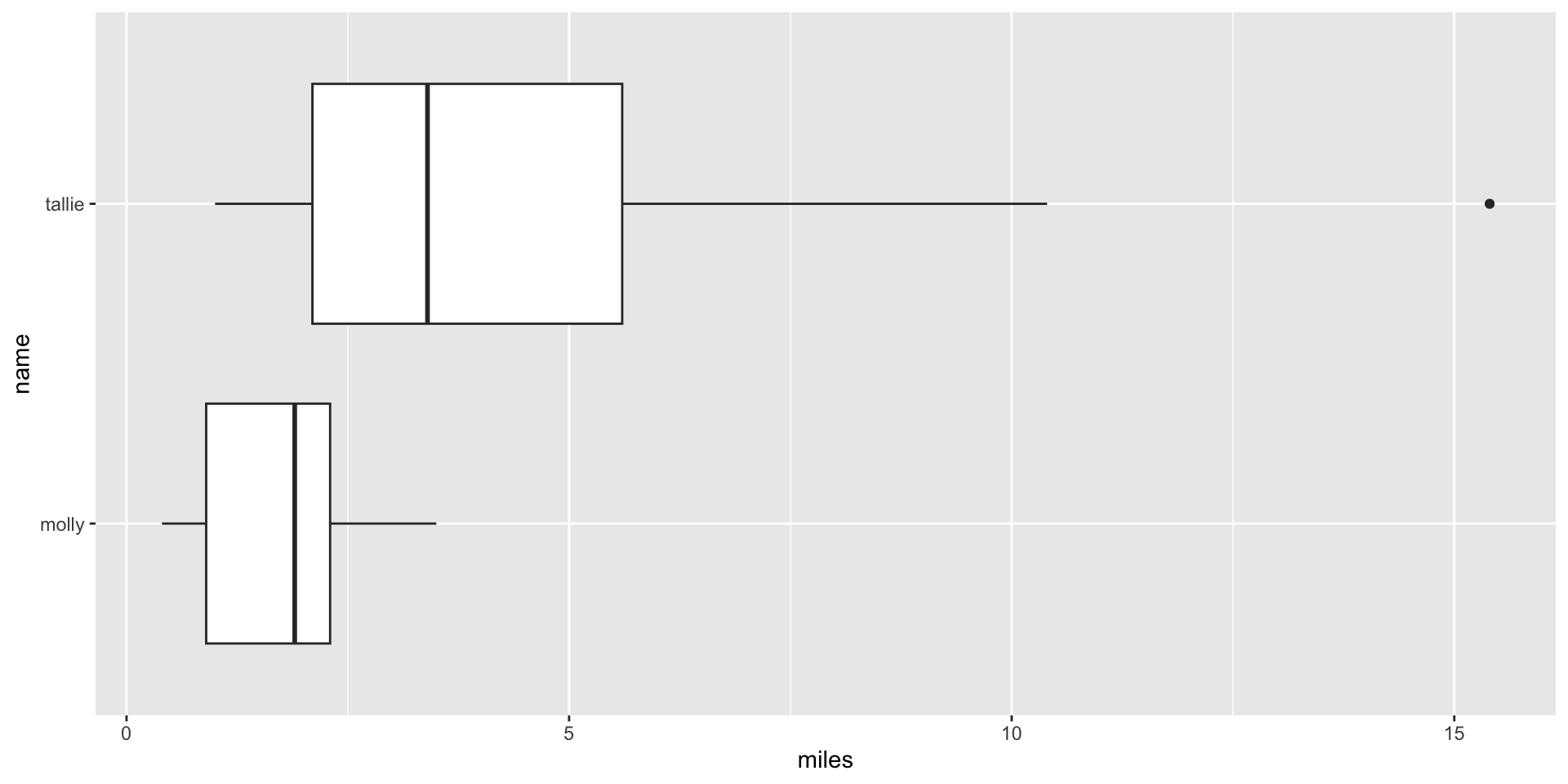
Communicating data summaries
The “Bar plots” philosophy: show as much as you can for the audience you’re presenting to
Summary statistics are often useful, but are a small part of the whole data story
Uncertainty is important! How can we responsibly communicate it?
All summaries are strongest when accompanied by additional data communication