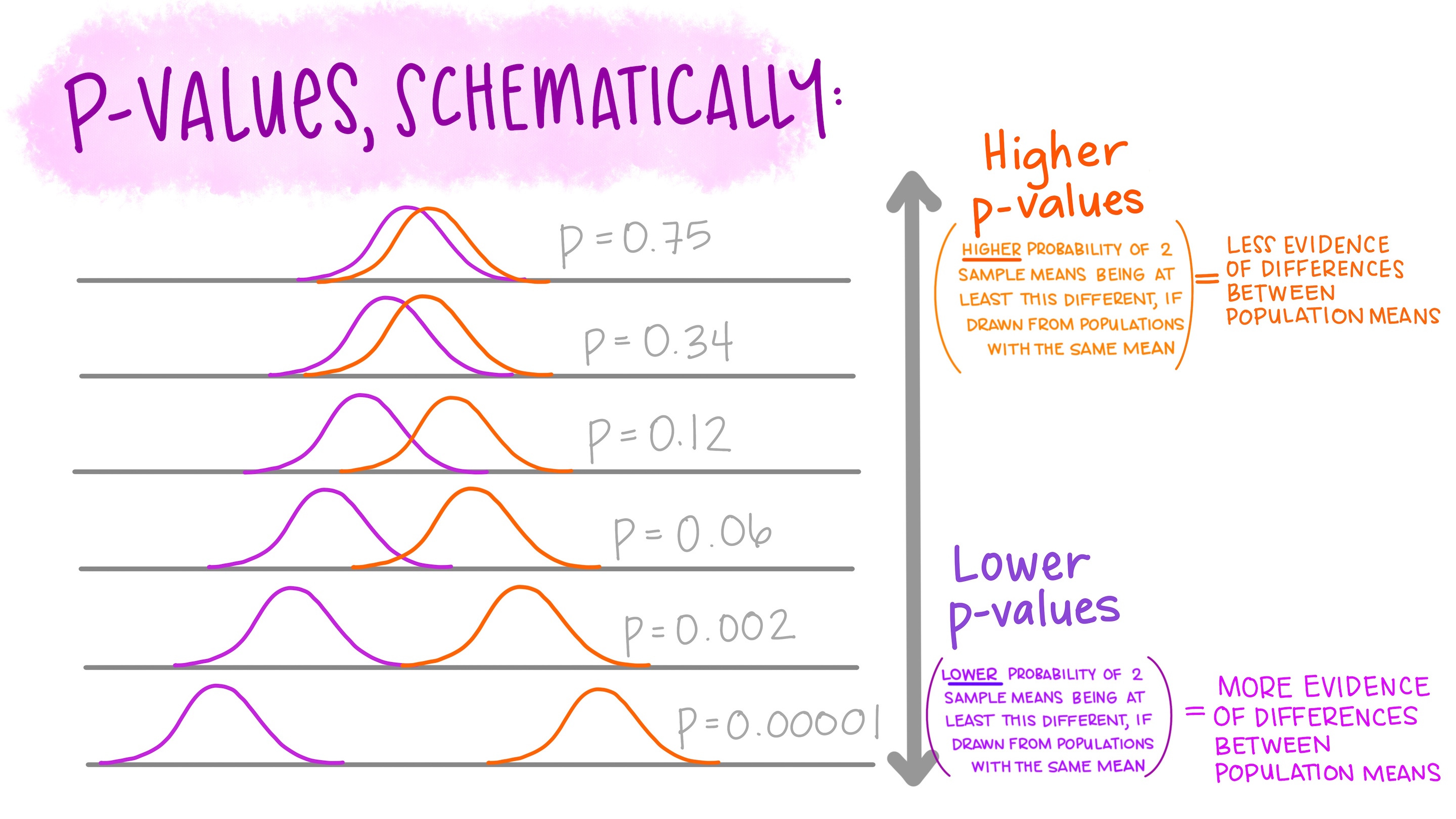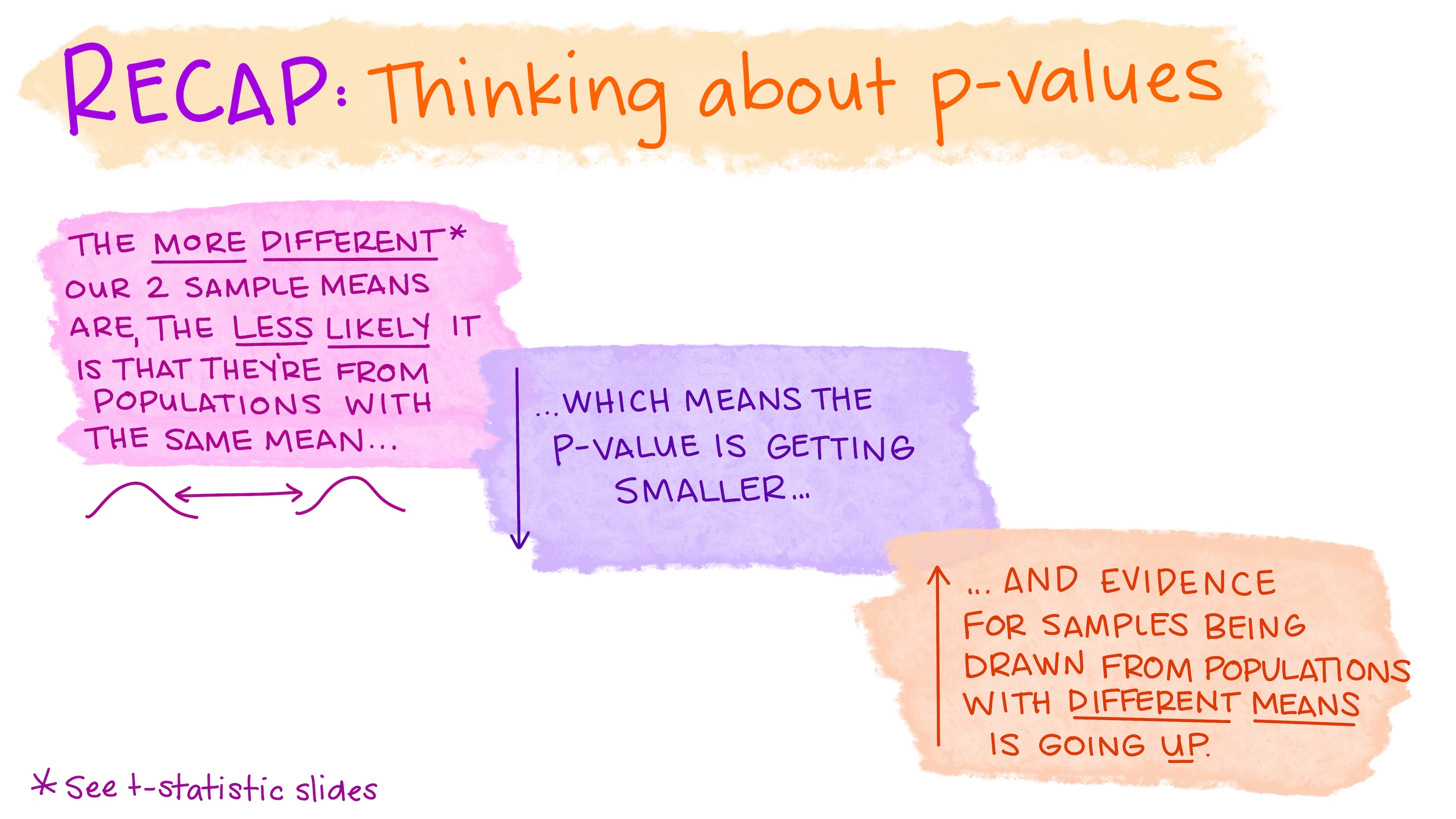
You’ll learn about hypothesis testing in EDS 222. Let’s just build a bit more intuition here.
A common question: are means from two samples so different (considering data spread and sample size) that we think we have enough evidence to reject a null hypothesis that they were drawn from populations with the same mean?
Caveat, assumptions, caveat (EDS 222)…